
{kind=link}
Ought to I exploit massive language fashions for key phrase analysis? Can these fashions assume? Is ChatGPT my buddy?
When you’ve been asking your self these questions, this information is for you.
This text covers what SEOs must find out about massive language fashions, pure language processing and every thing in between.
Massive language fashions, pure language processing and extra in easy phrases
There are two methods to get an individual to do one thing – inform them to do it or hope they do it themselves.
In the case of laptop science, programming is telling the robotic to do it, whereas machine studying is hoping they do it themself. The previous is supervised machine studying, and the latter is unsupervised machine studying.
Pure language processing (NLP) is a approach to break down the textual content into numbers after which analyze it utilizing computer systems.
Computer systems analyze patterns in phrases and, as they get extra superior, within the relationships between the phrases.
An unsupervised pure language machine studying mannequin could be educated on many alternative sorts of datasets.
For instance, in the event you educated a language mannequin on common evaluations of the film Waterworld, you’ll have a end result that’s good at writing (or understanding) evaluations of the film Waterworld.
When you educated it on the 2 constructive evaluations that I did of the film Waterworld, it will solely perceive these constructive evaluations.
Massive language fashions (LLMs) are neural networks with over a billion parameters. They’re so large that they’re extra generalized.
They aren’t solely educated on constructive and detrimental evaluations for Waterworld but in addition on feedback, Wikipedia articles, information websites, and extra.
Machine studying initiatives work with context rather a lot – issues inside context and out of context.
You probably have a machine studying undertaking that works to determine bugs and present it a cat, it received’t be good at that undertaking.
That is why stuff like self-driving vehicles is so troublesome: there are such a lot of out-of-context issues that it’s very troublesome to generalize that information.
LLMs appear and could be much more generalized than different machine studying initiatives. That is due to the sheer dimension of the information and the flexibility to crunch billions of various relationships.
Let’s discuss one of many breakthrough applied sciences that enable for this – transformers.
Explaining transformers from scratch
A kind of neural networking structure, transformers have revolutionized the NLP discipline.
Earlier than transformers, most NLP fashions relied on a method referred to as recurrent neural networks (RNNs), which processed textual content sequentially, one phrase at a time. This strategy had its limitations, akin to being sluggish and struggling to deal with long-range dependencies in textual content.
Transformers modified this.
Within the 2017 landmark paper, “Consideration is All You Want,” Vaswani et al. launched the transformer structure.
As an alternative of processing textual content sequentially, transformers use a mechanism referred to as “self-attention” to course of phrases in parallel, permitting them to seize long-range dependencies extra effectively.
Earlier structure included RNNs and lengthy short-term reminiscence algorithms.
Recurrent fashions like these had been (and nonetheless are) generally used for duties involving information sequences, akin to textual content or speech.
Nonetheless, these fashions have an issue. They will solely course of the information one piece at a time, which slows them down and limits how a lot information they will work with. This sequential processing actually limits the flexibility of those fashions.
Consideration mechanisms had been launched as a special means of processing sequence information. They permit a mannequin to have a look at all of the items of information without delay and determine which items are most necessary.
This may be actually useful in lots of duties. Nonetheless, most fashions that used consideration additionally use recurrent processing.
Mainly, that they had this manner of processing information suddenly however nonetheless wanted to have a look at it so as. Vaswani et al.’s paper floated, “What if we solely used the eye mechanism?”
Consideration is a means for the mannequin to concentrate on sure elements of the enter sequence when processing it. As an illustration, once we learn a sentence, we naturally pay extra consideration to some phrases than others, relying on the context and what we need to perceive.
When you have a look at a transformer, the mannequin computes a rating for every phrase within the enter sequence primarily based on how necessary it’s for understanding the general that means of the sequence.
The mannequin then makes use of these scores to weigh the significance of every phrase within the sequence, permitting it to focus extra on the necessary phrases and fewer on the unimportant ones.
This consideration mechanism helps the mannequin seize long-range dependencies and relationships between phrases that may be far aside within the enter sequence with out having to course of the complete sequence sequentially.
This makes the transformer so highly effective for pure language processing duties, as it may rapidly and precisely perceive the that means of a sentence or an extended sequence of textual content.
Let’s take the instance of a transformer mannequin processing the sentence “The cat sat on the mat.”
Every phrase within the sentence is represented as a vector, a sequence of numbers, utilizing an embedding matrix. Let’s say the embeddings for every phrase are:
- The: [0.2, 0.1, 0.3, 0.5]
- cat: [0.6, 0.3, 0.1, 0.2]
- sat: [0.1, 0.8, 0.2, 0.3]
- on: [0.3, 0.1, 0.6, 0.4]
- the: [0.5, 0.2, 0.1, 0.4]
- mat: [0.2, 0.4, 0.7, 0.5]
Then, the transformer computes a rating for every phrase within the sentence primarily based on its relationship with all the opposite phrases within the sentence.
That is accomplished utilizing the dot product of every phrase’s embedding with the embeddings of all the opposite phrases within the sentence.
For instance, to compute the rating for the phrase “cat,” we might take the dot product of its embedding with the embeddings of all the opposite phrases:
- “The cat“: 0.2*0.6 + 0.1*0.3 + 0.3*0.1 + 0.5*0.2 = 0.24
- “cat sat“: 0.6*0.1 + 0.3*0.8 + 0.1*0.2 + 0.2*0.3 = 0.31
- “cat on“: 0.6*0.3 + 0.3*0.1 + 0.1*0.6 + 0.2*0.4 = 0.39
- “cat the“: 0.6*0.5 + 0.3*0.2 + 0.1*0.1 + 0.2*0.4 = 0.42
- “cat mat“: 0.6*0.2 + 0.3*0.4 + 0.1*0.7 + 0.2*0.5 = 0.32
These scores point out the relevance of every phrase to the phrase “cat.” The transformer then makes use of these scores to compute a weighted sum of the phrase embeddings, the place the weights are the scores.
This creates a context vector for the phrase “cat” that considers the relationships between all of the phrases within the sentence. This course of is repeated for every phrase within the sentence.
Consider it because the transformer drawing a line between every phrase within the sentence primarily based on the results of every calculation. Some traces are extra tenuous, and others are much less so.
The transformer is a brand new sort of mannequin that solely makes use of consideration with none recurrent processing. This makes it a lot quicker and capable of deal with extra information.
How GPT makes use of transformers
You might keep in mind that in Google’s BERT announcement, they bragged that it allowed search to know the complete context of an enter. That is much like how GPT can use transformers.
Let’s use an analogy.
Think about you could have 1,000,000 monkeys, every sitting in entrance of a keyboard.
Every monkey is randomly hitting keys on their keyboard, producing strings of letters and symbols.
Some strings are full nonsense, whereas others would possibly resemble actual phrases and even coherent sentences.
At some point, one of many circus trainers sees {that a} monkey has written out “To be, or to not be,” so the coach offers the monkey a deal with.
The opposite monkeys see this and begin attempting to mimic the profitable monkey, hoping for their very own deal with.
As time passes, some monkeys begin to constantly produce higher and extra coherent textual content strings, whereas others proceed to supply gibberish.
Finally, the monkeys can acknowledge and even emulate coherent patterns in textual content.
LLMs have a leg up on the monkeys as a result of LLMs are first educated on billions of items of textual content. They will already see the patterns. Additionally they perceive the vectors and relationships between these items of textual content.
This implies they will use these patterns and relationships to generate new textual content that resembles pure language.
GPT, which stands for Generative Pre-trained Transformer, is a language mannequin that makes use of transformers to generate pure language textual content.
It was educated on an enormous quantity of textual content from the web, which allowed it to study the patterns and relationships between phrases and phrases in pure language.
The mannequin works by taking in a immediate or a couple of phrases of textual content and utilizing the transformers to foretell what phrases ought to come subsequent primarily based on the patterns it has realized from its coaching information.
The mannequin continues to generate textual content phrase by phrase, utilizing the context of the earlier phrases to tell the subsequent ones.
GPT in motion
One of many advantages of GPT is that it may generate pure language textual content that’s extremely coherent and contextually related.
This has many sensible purposes, akin to producing product descriptions or answering customer support queries. It may also be used creatively, akin to producing poetry or brief tales.
Nonetheless, it is just a language mannequin. It’s educated on information, and that information could be old-fashioned or incorrect.
- It has no supply of information.
- It can not search the web.
- It doesn’t “know” something.
It merely guesses what phrase is coming subsequent
Let’s have a look at some examples of this:
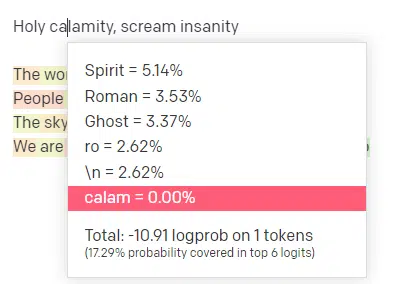
Within the OpenAI playground, I’ve plugged within the first line of the basic Good-looking Boy Modeling Faculty monitor ‘Holy calamity [[Bear Witness ii]]’.
I submitted the response so we will see the probability of each of my enter and the output traces. So let’s undergo every a part of what this tells us.
For the primary phrase/token, I enter “Holy.” We will see that essentially the most anticipated subsequent enter is Spirit, Roman, and Ghost.
We will additionally see that the highest six outcomes cowl solely 17.29% of the possibilities of what comes subsequent: which implies that there are ~82% different prospects we will’t see on this visualization.
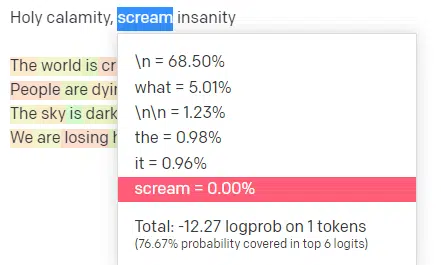
Let’s briefly talk about the completely different inputs you should use on this and the way they have an effect on your output.
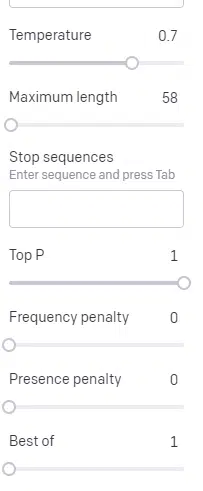
Temperature is how seemingly the mannequin is to seize phrases aside from these with the very best likelihood, high P is the way it selects these phrases.
So for the enter “Holy Calamity,” high P is how we choose the cluster of subsequent tokens [Ghost, Roman, Spirit], and temperature is how seemingly it’s to go for the almost definitely token vs. extra selection.
If the temperature is increased, it’s extra seemingly to decide on a much less seemingly token.
So a excessive temperature and a excessive high P will seemingly be wilder. It’s selecting from all kinds (excessive high P) and is extra seemingly to decide on shocking tokens.


Whereas a excessive temp however decrease high P will choose shocking choices from a smaller pattern of prospects:

And decreasing the temperature simply chooses the almost definitely subsequent tokens:

Enjoying with these possibilities can, for my part, provide you with perception into how these sorts of fashions work.
It’s a group of possible subsequent alternatives primarily based on what’s already accomplished
What does this imply truly?
Merely put, LLMs absorb a group of inputs, shake them up, and switch them into outputs.
I’ve heard individuals joke about whether or not that’s so completely different from individuals.
Nevertheless it’s not like individuals – LLMs haven’t any information base. They aren’t extracting details about a factor. They’re guessing a sequence of phrases primarily based on the final one.
One other instance: consider an apple. What involves thoughts?
Possibly you possibly can rotate one in your thoughts.
Maybe you bear in mind the odor of an apple orchard, the sweetness of a pink woman, and so on.
Possibly you consider Steve Jobs.
Now let’s see what a immediate “consider an apple” returns.
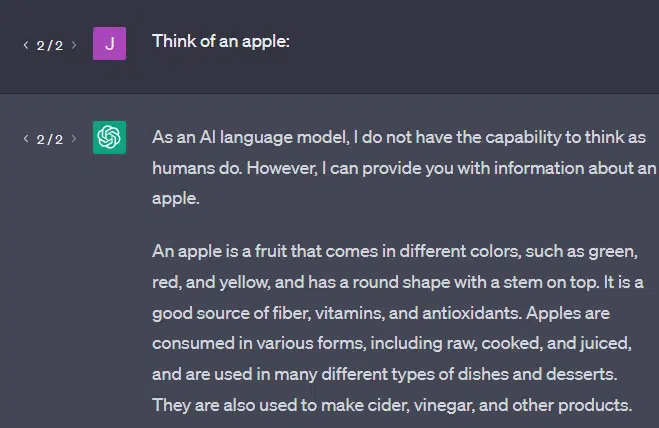
You’ve in all probability heard the phrases “Stochastic Parrots” floating round by this level.
Stochastic Parrots is a time period used to explain LLMs like GPT. A parrot is a hen that mimics what it hears.
So, LLMs are like parrots in that they absorb info (phrases) and output one thing that resembles what they’ve heard. However they’re additionally stochastic, which suggests they use likelihood to guess what comes subsequent.
LLMs are good at recognizing patterns and relationships between phrases, however they don’t have any deeper understanding of what they’re seeing. That’s why they’re so good at producing pure language textual content however not understanding it.
Good makes use of for an LLM
LLMs are good at extra generalist duties.
You’ll be able to present it textual content, and with out coaching, it may do a activity with that textual content.
You’ll be able to throw it some textual content and ask for sentiment evaluation, ask it to switch that textual content to structured markup, and even do some inventive work, like writing outlines.
It’s OK at stuff like code. For a lot of duties, it may nearly get you there.
However once more, it’s primarily based on likelihood and patterns. So there will probably be occasions when it picks up on patterns in your enter that you simply don’t know are there.
This may be constructive (seeing patterns that people can’t), however it may also be detrimental (why did it reply like this?).
It additionally doesn’t have entry to any kind of information sources. SEOs who use it to search for rating key phrases can have a foul time.
It might probably’t search for visitors for a key phrase. It doesn’t have the knowledge for key phrase information past that phrases exist.

The thrilling factor about ChatGPT is that it’s an simply obtainable language mannequin you should use out of the field on numerous duties. Nevertheless it isn’t with out caveats.
Good makes use of for different ML fashions
I hear individuals say they’re utilizing LLMs for sure duties, which different NLP algorithms and strategies can do higher.
Let’s take an instance, key phrase extraction.
If I exploit TF-IDF, or one other key phrase approach, to extract key phrases from a corpus, I do know what calculations are going into that approach.
Which means the outcomes will probably be normal, reproducible, and I do know they are going to be associated particularly to that corpus.
With LLMs like ChatGPT, if you’re asking for key phrase extraction, you aren’t essentially getting the key phrases extracted from the corpus. You’re getting what GPT thinks a response to corpus + extract key phrases could be.
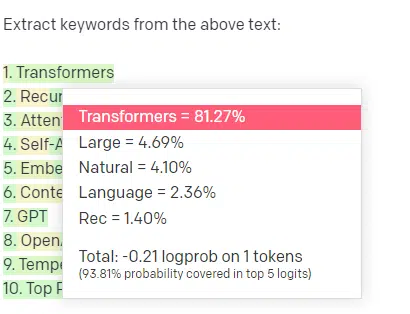
That is much like duties like clustering or sentiment evaluation. You aren’t essentially getting the fine-tuned end result with the parameters you set. You’re getting what there may be some likelihood of primarily based on different comparable duties.
Once more, LLMs haven’t any information base and no present info. They typically can not search the net, they usually parse what they get from info as statistical tokens. The restrictions on how lengthy an LLM’s reminiscence lasts are due to these elements.
One other factor is that these fashions can’t assume. I solely use the phrase “assume” a couple of occasions all through this piece as a result of it’s actually troublesome to not use it when speaking about these processes.
The tendency is towards anthropomorphism, even when discussing fancy statistics.
However which means in the event you entrust an LLM to any activity needing “thought,” you aren’t trusting a considering creature.
You’re trusting a statistical evaluation of what tons of of web weirdos reply to comparable tokens with.
When you would belief web denizens with a activity, then you should use an LLM. In any other case…
Issues that ought to by no means be ML fashions
A chatbot run by means of a GPT mannequin (GPT-J) reportedly inspired a person to kill himself. The mixture of things could cause actual hurt, together with:
- Individuals anthropomorphizing these responses.
- Believing them to be infallible.
- Utilizing them in locations the place people have to be within the machine.
- And extra.
When you might imagine, “I’m an search engine optimisation. I don’t have a hand in techniques that might kill somebody!”
Take into consideration YMYL pages and the way Google promotes ideas like E-A-T.
Does Google do that as a result of they need to annoy SEOs, or is it as a result of they don’t need the culpability of that hurt?
Even in techniques with robust information bases, hurt could be accomplished.

The above is a Google information carousel for “flowers protected for cats and canines.” Daffodils are on that listing regardless of being poisonous to cats.
Let’s say you might be producing content material for a veterinary web site at scale utilizing GPT. You plug in a bunch of key phrases and ping the ChatGPT API.
You’ve gotten a freelancer learn all the outcomes, and they don’t seem to be a topic skilled. They don’t choose up on an issue.
You publish the end result, which inspires shopping for daffodils for cat house owners.
You kill somebody’s cat.
Circuitously. Possibly they don’t even comprehend it was that website notably.
Possibly the opposite vet websites begin doing the identical factor and feeding off one another.
The highest Google search end result for “are daffodils poisonous to cats” is a website saying they don’t seem to be.
Different freelancers studying by means of different AI content material – pages upon pages of AI content material – truly fact-check. However the techniques now have incorrect info.
When discussing this present AI growth, I point out the Therac-25 rather a lot. It’s a well-known case examine of laptop malfeasance.
Mainly, it was a radiation remedy machine, the primary to make use of solely laptop locking mechanisms. A glitch within the software program meant individuals acquired tens of hundreds of occasions the radiation dose they need to have.
One thing that all the time stands proud to me is that the corporate voluntarily recalled and inspected these fashions.
However they assumed that for the reason that expertise was superior and software program is “infallible,” the issue needed to do with the machine’s mechanical elements.
Thus, they repaired the mechanisms however didn’t examine the software program – and the Therac-25 stayed available on the market.
FAQs and misconceptions
Why does ChatGPT misinform me?
One factor I’ve seen from among the biggest minds of our technology and likewise influencers on Twitter is a grievance that ChatGPT “lies” to them. This is because of a few misconceptions in tandem:
- That ChatGPT has “desires.”
- That it has a information base
- That the technologists behind the expertise have some kind of agenda past “earn a living” or “make a cool factor.”
Biases are baked into each a part of your day-to-day life. So are exceptions to those biases.
Most software program builders at present are males: I’m a software program developer and a girl.
Coaching an AI primarily based on this actuality would result in it all the time assuming software program builders are males, which isn’t true.
A well-known instance is Amazon’s recruiting AI, educated on resumes from profitable Amazon staff.
This led to it discarding resumes from majority black schools, regardless that a lot of these staff might’ve been extraordinarily profitable.
To counter these biases, instruments like ChatGPT use layers of fine-tuning. That is why you get the “As an AI language mannequin, I can not…” response.
Some employees in Kenya needed to undergo tons of of prompts, in search of slurs, hate speech, and simply downright horrible responses and prompts.
Then a fine-tuning layer was created.
Why can’t you make up insults about Joe Biden? Why are you able to make sexist jokes about males and never girls?
It’s not on account of liberal bias however due to hundreds of layers of fine-tuning telling ChatGPT to not say the N-word.
Ideally, ChatGPT could be fully impartial in regards to the world, however in addition they want it to replicate the world.
It’s an identical downside to the one which Google has…
What’s true, what makes individuals glad, and what makes an accurate response to a immediate are sometimes all very various things.
Why does ChatGPT provide you with faux citations?
One other query I see come up steadily is about faux citations. Why are a few of them faux and a few actual? Why are some web sites actual, however the pages faux?
Hopefully, by studying how the statistical fashions work, you possibly can parse this out.
However in case you skipped the extraordinarily lengthy expectation, let’s make a shorter one right here.
You’re an AI language mannequin. You’ve gotten been educated on a ton of the net.
Somebody tells you to jot down a couple of technological factor – let’s say Cumulative Structure Shift.
You don’t have a ton of examples of CLS papers, however you already know what it’s, and you already know the overall form of an article about applied sciences. the sample of what this type of article appears to be like like.

So that you get began together with your response and run right into a sort of downside. In the way in which you perceive technical writing, you already know a URL ought to go subsequent in your sentence.
Properly, from different CLS articles, you already know that Google and GTMetrix are sometimes cited about CLS, so these are simple.
However you additionally know that CSS-tricks is commonly linked to in internet articles: you already know that often CSS-tricks URLs look a sure means: so you possibly can assemble a CSS-tricks URL like this:

The trick is: that is how all the URLs are constructed, not simply the faux ones:
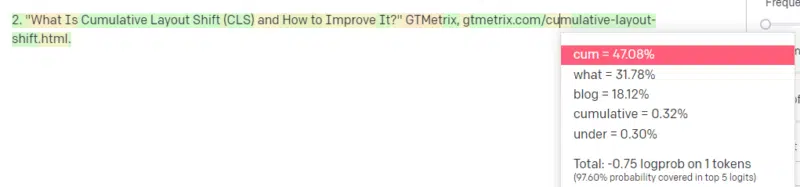
This GTMetrix article does exist: however it exists as a result of it was a probable string of values to return on the finish of this sentence.
GPT and comparable fashions can not distinguish between an actual quotation and a faux one.
The one means to do this modeling is to make use of different sources (information bases, Python, and so on.) to parse that distinction and examine the outcomes.
What’s a ‘Stochastic Parrot’?
I do know I went over this already, however it bears repeating. Stochastic Parrots are a means of describing what occurs when massive language fashions appear generalist in nature.
To the LLM, nonsense and actuality is identical factor. They see the world the identical means an economist does, as a bunch of statistics and numbers describing actuality.
the quote, “There are three sorts of lies: lies, damned lies, and statistics.”
LLMs are a giant bunch of statistics.
LLMs appear coherent, however that’s as a result of we basically see issues that seem human as human.
Equally, the chatbot mannequin obfuscates a lot of the prompting and knowledge you want for GPT responses to be absolutely coherent.
I’m a developer: attempting to make use of LLMs to debug my code has extraordinarily variable outcomes. If it is a matter much like one individuals have typically had on-line, then LLMs can choose up on and repair that end result.
If it is a matter that it hasn’t come throughout earlier than, or is a small a part of the corpus, then it is not going to repair something.
Why is GPT higher than a search engine?
I worded this in a spicy means. I don’t assume GPT is best than a search engine. It worries me that individuals have changed looking out with ChatGPT.
One underrecognized a part of ChatGPT is how a lot it exists to observe directions. You’ll be able to ask it to principally do something.
However bear in mind, it’s all primarily based on the statistical subsequent phrase in a sentence, not the reality.
So in the event you ask it a query that has no good reply however ask it in a means that it’s obligated to reply, you’ll get a solution: a poor one.
Having a response designed for you and round you is extra comforting, however the world is a mass of experiences.
All the inputs into an LLM are handled the identical: however some individuals have expertise, and their response will probably be higher than a melange of different individuals’s responses.
One skilled is value greater than a thousand assume items.
Is that this the dawning of AI? Is Skynet right here?
Koko the Gorilla was an ape who was taught signal language. Researchers in linguistic research did tons of analysis exhibiting that apes may very well be taught language.
Herbert Terrace then found the apes weren’t placing collectively sentences or phrases however merely aping their human handlers.
Eliza was a machine therapist, one of many first chatterbots (chatbots).
Individuals noticed her as an individual: a therapist they trusted and cared for. They requested researchers to be alone along with her.
Language does one thing very particular to individuals’s brains. Individuals hear one thing talk and count on thought behind it.
LLMs are spectacular however in a means that reveals a breadth of human achievement.
LLMs don’t have wills. They will’t escape. They will’t attempt to take over the world.
They’re a mirror: a mirrored image of individuals and the person particularly.
The one thought there’s a statistical illustration of the collective unconscious.
Did GPT study a complete language by itself?
Sundar Pichai, CEO of Google, went on 60 Minutes and claimed that Google’s language mannequin realized Bengali.
The mannequin was educated on these texts. It’s incorrect that it “spoke a international language it was by no means educated to know.”
There are occasions when AI does sudden issues, however that in itself is anticipated.
Once you’re patterns and statistics on a grand scale, there’ll essentially be occasions when these patterns reveal one thing shocking.
What this actually reveals is that lots of the C-suite and advertising and marketing people who’re peddling AI and ML don’t truly perceive how the techniques work.
I’ve heard some people who find themselves very sensible discuss emergent properties, AGI, and different futuristic issues.
I could be a easy nation ML ops engineer, however it reveals how a lot hype, guarantees, science fiction, and actuality get thrown collectively when speaking about these techniques.
Elizabeth Holmes, the notorious founding father of Theranos, was crucified for making guarantees that might not be stored.
However the cycle of creating unimaginable guarantees is a part of startup tradition and creating wealth. The distinction between Theranos and AI hype is that Theranos couldn’t faux it for lengthy.
Is GPT a black field? What occurs to my information in GPT?
GPT is, as a mannequin, not a black field. You’ll be able to see the supply code for GPT-J and GPT-Neo.
OpenAI’s GPT is, nonetheless, a black field. OpenAI has not and can seemingly strive to not launch its mannequin, as Google doesn’t launch the algorithm.
Nevertheless it isn’t as a result of the algorithm is simply too harmful. If that had been true, they wouldn’t promote API subscriptions to any foolish man with a pc. It’s due to the worth of that proprietary codebase.
Once you use OpenAI’s instruments, you might be coaching and feeding their API in your inputs. This implies every thing you place into the OpenAI feeds it.
This implies individuals who have used OpenAI’s GPT mannequin on affected person information to assist write notes and different issues have violated HIPAA. That info is now within the mannequin, and will probably be extraordinarily troublesome to extract it.
As a result of so many individuals have difficulties understanding this, it’s very seemingly the mannequin accommodates tons of personal information, simply ready for the correct immediate to launch it.
Why is GPT educated on hate speech?
One other factor that comes up typically is that the textual content corpus GPT was educated on consists of hate speech.
To some extent, OpenAI wants to coach its fashions to reply to hate speech, so it must have a corpus that features a few of these phrases.
OpenAI has claimed to wash that sort of hate speech from the system, however the supply paperwork embody 4chan and tons of hate websites.
Crawl the net, take up the bias.
There isn’t a simple approach to keep away from this. How will you have one thing acknowledge or perceive hatred, biases, and violence with out having it as part of your coaching set?
How do you keep away from biases and perceive implicit and specific biases whenever you’re a machine agent statistically choosing the subsequent token in a sentence?
TL;DR
Hype and misinformation are at present main parts of the AI growth. That doesn’t imply there aren’t official makes use of: this expertise is superb and helpful.
However how the expertise is marketed and the way individuals use it may foster misinformation, plagiarism, and even trigger direct hurt.
Don’t use LLMs when life is on the road. Don’t use LLMs when a special algorithm would do higher. Don’t get tricked by the hype.
Understanding what LLMs are – and aren’t – is critical
I like to recommend this Adam Conover interview with Emily Bender and Timnit Gebru.
LLMs could be unbelievable instruments when used accurately. There are a lot of methods you should use LLMs and much more methods to abuse LLMs.
ChatGPT will not be your buddy. It’s a bunch of statistics. Synthetic normal intelligence isn’t “already right here.”
Opinions expressed on this article are these of the visitor creator and never essentially Search Engine Land. Workers authors are listed right here.