
{kind=link}
Because the introduction of generative AI, giant language fashions (LLMs) have conquered the world and located their method into search engines like google.
However is it potential to proactively affect AI efficiency by way of giant language mannequin optimization (LLMO) or generative AI optimization (GAIO)?
This text discusses the evolving panorama of website positioning and the unsure way forward for LLM optimization in AI-powered search engines like google, with insights from information science consultants.
What’s LLM optimization or generative AI optimization (GAIO)?
GAIO goals to assist firms place their manufacturers and merchandise within the outputs of main LLMs, corresponding to GPT and Google Bard, outstanding as these fashions can affect many future buy selections.
For instance, for those who search Bing Chat for one of the best trainers for a 96-kilogram runner who runs 20 kilometers per week, Brooks, Saucony, Hoka and New Stability footwear shall be advised.
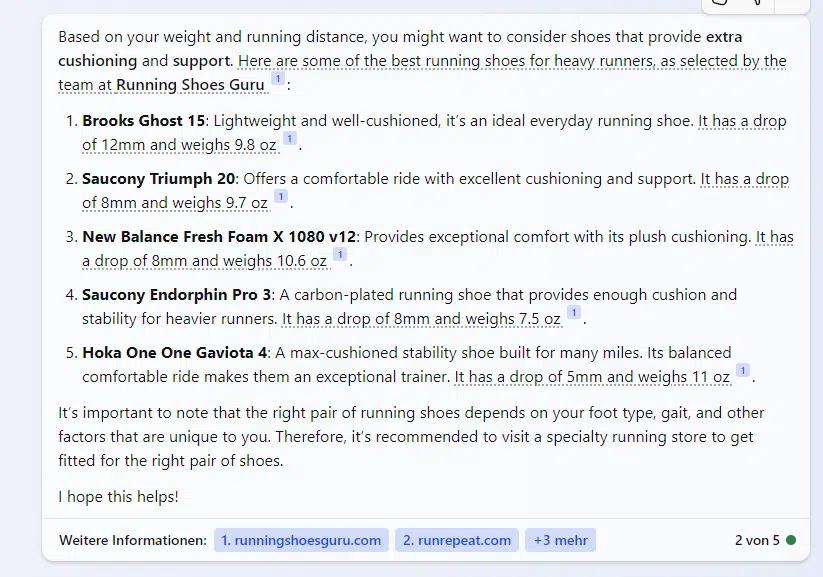
While you ask Bing Chat for secure, family-friendly automobiles which might be large enough for procuring and journey, it suggests Kia, Toyota, Hyundai and Chevrolet fashions.
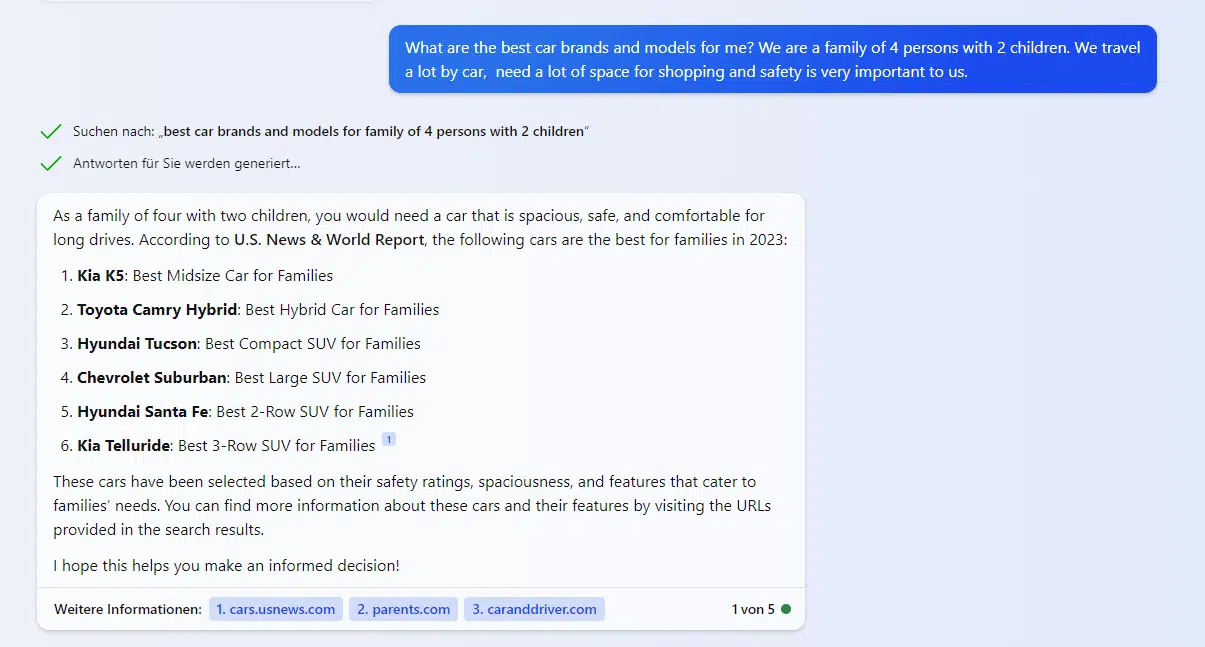
The strategy of potential strategies corresponding to LLM optimization is to offer choice to sure manufacturers and merchandise when coping with corresponding transaction-oriented questions.
How are these suggestions made?
Solutions from Bing Chat and different generative AI instruments are all the time contextual. The AI largely makes use of impartial secondary sources corresponding to commerce magazines, information websites, affiliation and public establishment web sites, and blogs as a supply for suggestions.
The output of generative AI is predicated on the dedication of statistical frequencies. The extra usually phrases seem in sequence within the supply information, the extra seemingly it’s that the specified phrase is the proper one within the output.
Phrases ceaselessly talked about within the coaching information are statistically extra comparable or semantically extra intently associated.
Which manufacturers and merchandise are talked about in a sure context could be defined by the way in which LLMs work.
LLMs in motion
Fashionable transformer-based LLMs corresponding to GPT or Bard are based mostly on a statistical evaluation of the co-occurrence of tokens or phrases.
To do that, texts and information are damaged down into tokens for machine processing and positioned in semantic areas utilizing vectors. Vectors may also be complete phrases (Word2Vec), entities (Node2Vec), and attributes.
In semantics, the semantic house can also be described as an ontology. Since LLMs rely extra on statistics than semantics, they don’t seem to be ontologies. Nonetheless, the AI will get nearer to semantic understanding because of the quantity of knowledge.
Semantic proximity could be decided by Euclidean distance or cosine angle measure in semantic house.

If an entity is ceaselessly talked about in reference to sure different entities or properties within the coaching information, there’s a excessive statistical likelihood of a semantic relationship.
The tactic of this processing is known as transformer-based pure language processing.
NLP describes a course of of remodeling pure language right into a machine-understandable kind that allows communication between people and machines.
NLP contains pure language understanding (NLU) and pure language era (NLG).
When coaching LLMs, the main target is on NLU, and when outputting AI-generated outcomes, the main target is on NLG.
Figuring out entities by way of named entity extraction performs a particular function in semantic understanding and an entity’s that means inside a thematic ontology.
As a result of frequent co-occurrence of sure phrases, these vectors transfer nearer collectively within the semantic house: the semantic proximity will increase, and the likelihood of membership will increase.
The outcomes are output by way of NLG based on statistical likelihood.
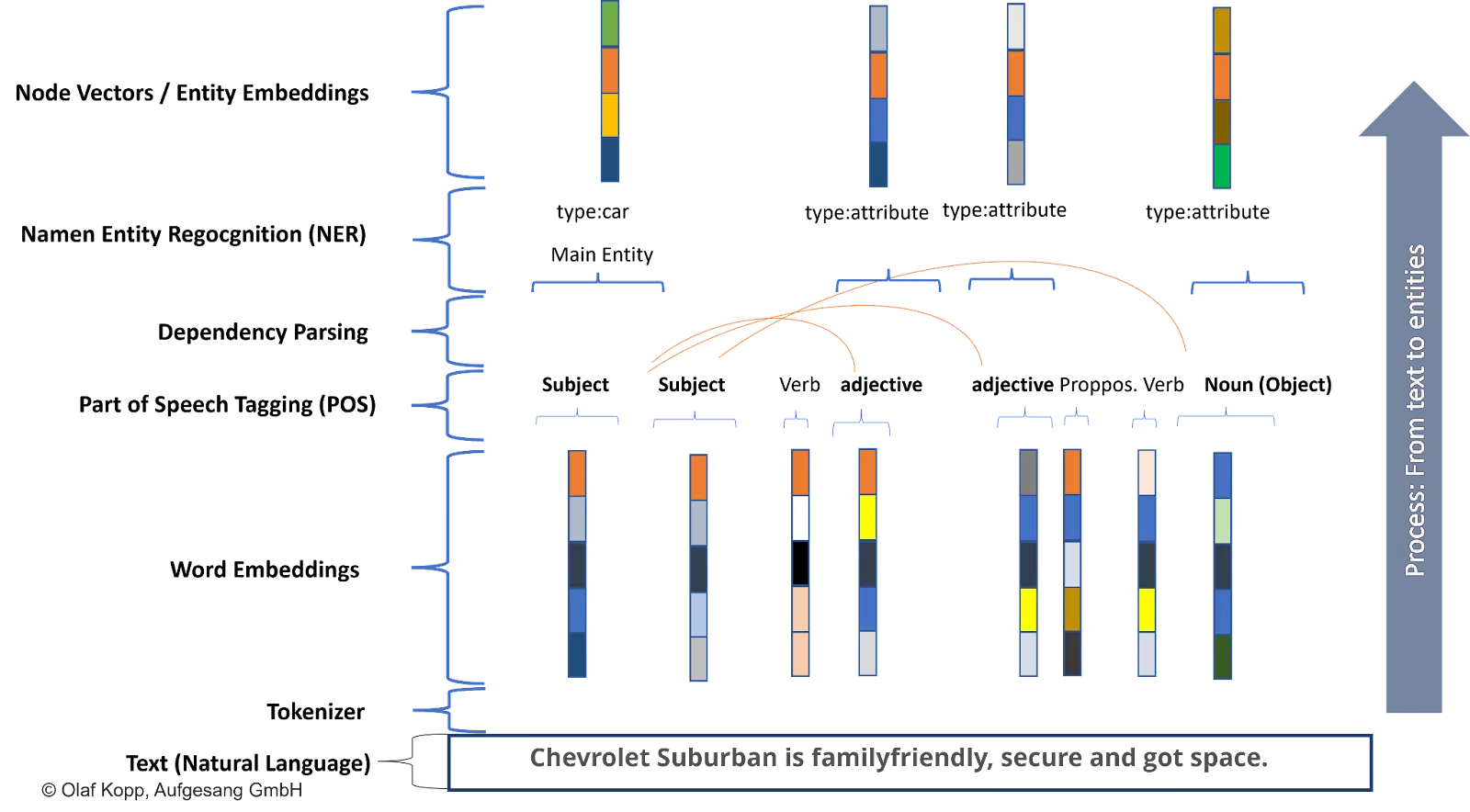
For instance, suppose the Chevrolet Suburban is commonly talked about within the context of household and security.
In that case, the LLM can affiliate this entity with sure attributes corresponding to secure or family-friendly. There’s a excessive statistical likelihood that this automobile mannequin is related to these attributes.
Get the each day publication search entrepreneurs depend on.
Can the outputs of generative AI be influenced proactively?
I have not heard conclusive solutions to this query, solely unfounded hypothesis.
To get nearer to a solution, it is sensible to strategy it from an information science perspective. In different phrases, from individuals who know the way giant language fashions work.
I requested three information science consultants from my community. Right here’s what they mentioned.
Kai Spriestersbach, Utilized AI researcher and website positioning veteran:
- “Theoretically, it is definitely potential, and it can’t be dominated out that political actors or states would possibly go to such lengths. Frankly, I truly assume some do. Nonetheless, from a purely sensible standpoint, for enterprise advertising, I do not see this as a viable method to deliberately affect the “opinion” or notion of an AI, except it is also influencing public opinion on the identical time, as an example, via conventional PR or branding.
- “With business giant language fashions, it isn’t publicly disclosed what coaching information is used, nor how it’s filtered and weighted. Furthermore, business suppliers make the most of alignment methods to make sure the AI’s responses are as impartial and uncontroversial as potential, no matter the coaching information.
- “Finally, one must be sure that over 50% of the statements within the coaching information mirror the specified sentiment, which within the excessive case means flooding the online with posts and texts, hoping they get included into the coaching information.”
Barbara Lampl, Behavioral mathematician and COO at Genki:
- “It is theoretically potential to affect an LLM via a synchronized effort of content material, PR, and mentions, the info science mechanics will underscore the growing challenges and diminishing rewards of such an strategy.
- “The endeavor’s complexity, when analyzed via the lens of knowledge science, turns into much more pronounced and arguably unfeasible.”
Philip Ehring, Head of Enterprise Intelligence at Reverse-Retail:
- “The dynamics between LLMs and techniques like ChatGPT and website positioning in the end stay the identical on the finish of the equation. Solely the attitude of optimization will change to a different device, that’s in reality nothing greater than a greater interface for classical data retrieval techniques…
- “In the long run, it is an optimization for a hybrid metasearch engine with a pure language person interface that summarizes the outcomes for you.”
The next factors could be constituted of an information science perspective:
- For big business language fashions, the coaching database isn’t public, and tuning methods are used to make sure impartial and uncontroversial responses. To embed the specified opinion within the AI, greater than 50% of the coaching information must mirror that opinion, which might be extraordinarily troublesome to affect.
- It’s troublesome to make a significant influence because of the enormous quantity of knowledge and statistical significance.
- The dynamics of community proliferation, time elements, mannequin regularization, suggestions loops, and financial prices are obstacles.
- As well as, the delay in mannequin updates makes it troublesome to affect.
- As a result of giant variety of co-occurrences that must be created, relying in the marketplace, it’s only potential to affect the output of a generative AI with regard to at least one’s personal merchandise and model with better dedication to PR and advertising.
- One other problem is to determine the sources that shall be used as coaching information for the LLMs.
- The core dynamics between LLMs and techniques like ChatGPT or BARD and website positioning stay constant. The one change is within the optimization perspective, which shifts to a greater interface for classical data retrieval.
- ChatGPT’s fine-tuning course of entails a reinforcement studying layer that generates responses based mostly on discovered contexts and prompts.
- Conventional search engines like google like Google and Bing are used to focus on high quality content material and domains like Wikipedia or GitHub. The mixing of fashions like BERT into these techniques has been a identified development. Google’s BERT modifications how data retrieval understands person queries and contexts.
- Consumer enter has lengthy directed the main target of net crawls for LLMs. The chance of an LLM utilizing content material from a crawl for coaching is influenced by the doc’s findability on the net.
- Whereas LLMs excel at computing similarities, they are not as proficient at offering factual solutions or fixing logical duties. To deal with this, Retrieval-Augmented Technology (RAG) makes use of exterior information shops to supply higher, sourced solutions.
- The mixing of net crawling affords twin advantages: enhancing ChatGPT’s relevance and coaching, and enhancing website positioning. A problem stays in human labeling and rating of prompts and responses for reinforcement studying.
- The prominence of content material in LLM coaching is influenced by its relevance and discoverability. The influence of particular content material on an LLM is difficult to quantify, however having one’s model acknowledged inside a context is a major achievement.
- RAG mechanics additionally enhance the standard of responses through the use of higher-ranked content material. This presents an optimization alternative by aligning content material with potential solutions.
- The evolution in website positioning is not a very new strategy however a shift in perspective. It entails understanding which search engines like google are prioritized by techniques like ChatGPT, incorporating prompt-generated key phrases into analysis, concentrating on related pages for content material, and structuring content material for optimum point out in responses.
- Finally, the aim is to optimize for a hybrid metasearch engine with a pure language interface that summarizes outcomes for customers.
How may the coaching information for the LLMs be chosen?
There are two potential approaches right here: E-E-A-T and rating.
We will assume that the suppliers of the well-known LLMs solely use sources as coaching information that meet a sure high quality normal and are reliable.
There could be a method to choose these sources utilizing Google’s E-E-A-T idea. Relating to entities, Google can use the Data Graph for fact-checking and fine-tuning the LLM.

The second strategy, as advised by Philipp Ehring, is to pick out coaching information based mostly on relevance and high quality decided by the precise rating course of. So, top-ranking content material to the corresponding queries and prompts are robotically used for coaching the LLMs.
This strategy assumes that the data retrieval wheel doesn’t need to be reinvented and that search engines like google depend on established analysis procedures to pick out coaching information. This might then embrace E-E-A-T along with relevance analysis.
Nonetheless, assessments on Bing Chat and SGE haven’t proven any clear correlations between the referenced sources and the rankings.
Influencing AI-powered website positioning
It stays to be seen whether or not LLM optimization or GAIO will actually change into a reputable technique for influencing LLMs when it comes to their very own targets.
On the info science aspect, there’s skepticism. Some SEOs consider in it.
If that is so, there are the next targets that have to be achieved:
- Set up your individual media by way of E-E-A-T as a supply of coaching information.
- Generate mentions of your model and merchandise in certified media.
- Create co-competitions of your individual model with different related entities and attributes in certified media.
- Turn into a part of the data graph.
I’ve defined what measures to take to realize this within the article Find out how to enhance E-A-T for web sites and entities.
The possibilities of success with LLM optimization enhance with the dimensions of the market. The extra area of interest a market is, the better it’s to place your self as a model within the respective thematic context.
Because of this fewer co-occurrences within the certified media are required to be related to the related attributes and entities within the LLMs. The bigger the market, the harder that is, as many market contributors have giant PR and advertising assets and an extended historical past.
GAIO or LLM optimization requires considerably extra assets than basic website positioning to affect public notion.
At this level, I wish to seek advice from my idea of Digital Authority Administration. You possibly can learn extra about this within the article Authority Administration: A New Self-discipline within the Age of SGE and E-E-A-T.
Suppose LLM optimization seems to be a wise website positioning technique. In that case, giant manufacturers could have vital benefits in search engine positioning and generative AI outcomes sooner or later as a consequence of their PR and advertising assets.
One other perspective is that one can proceed in SEO as earlier than since well-ranking content material may also be used for coaching the LLMs concurrently. There, one also needs to take note of co-occurrences between manufacturers/merchandise and attributes or different entities and optimize for them.
Nonetheless, assessments on Bing Chat and SBU haven’t but proven clear correlations between referenced sources and rankings.
Which of those approaches would be the future for website positioning is unclear and can solely change into obvious when SGE is lastly launched.
Opinions expressed on this article are these of the visitor creator and never essentially Search Engine Land. Workers authors are listed right here.