
{kind=link}
Search is difficult, as Seth Godin wrote in 2005.
I imply, if we expect search engine optimisation is difficult (and it’s) think about when you had been making an attempt to construct a search engine in a world the place:
- The customers differ dramatically and alter their preferences over time.
- The expertise they entry search advances each day.
- Opponents nipping at your heels continually.
On prime of that, you’re additionally coping with pesky SEOs making an attempt to sport your algorithm achieve insights into how greatest to optimize to your guests.
That’s going to make it rather a lot more durable.
Now think about if the principle applied sciences you might want to lean on to advance got here with their very own limitations – and, maybe worse, large prices.
Effectively, when you’re one of many writers of the not too long ago printed paper, “Finish-to-Finish Question Time period Weighting” you see this as a possibility to shine.
What’s end-to-end question time period weighting?
Finish-to-end question time period weighting refers to a technique the place the burden of every time period in a question is set as a part of the general mannequin, with out counting on manually programmed or conventional time period weighting schemes or different unbiased fashions.
What does that appear to be?
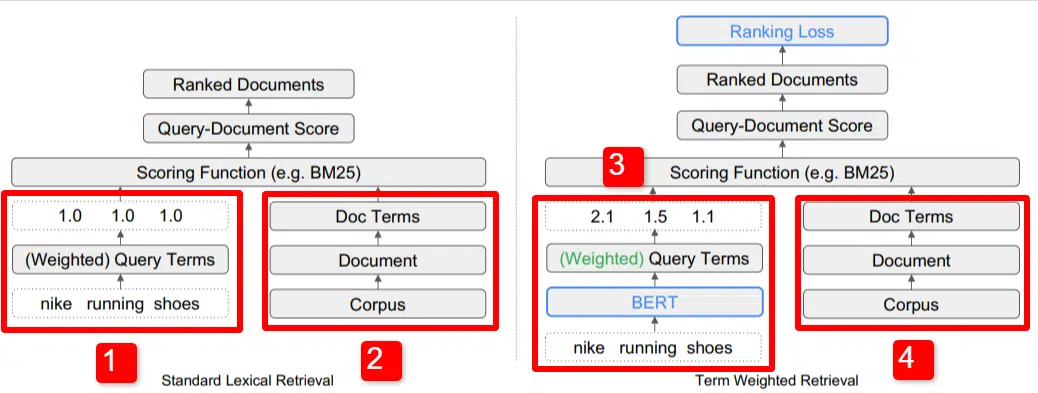
Right here we see an illustration of one in every of the important thing differentiators of the mannequin outlined within the paper (Determine 1, particularly).
On the fitting facet of the usual mannequin (2) we see the identical as we do with the proposed mannequin (4), which is the corpus (full set of paperwork within the index), resulting in the paperwork, resulting in the phrases.
This illustrates the precise hierarchy into the system, however you may casually consider it in reverse, from the highest down. Now we have phrases. We search for paperwork with these phrases. These paperwork are within the corpus of all of the paperwork we learn about.
To the decrease left (1) in the usual Data Retrieval (IR) structure, you’ll discover that there isn’t any BERT layer. The question used of their illustration (nike trainers) enters the system, and the weights are computed independently of the mannequin and handed to it.
Within the illustration right here, the weights are passing equally among the many three phrases within the question. Nonetheless, it doesn’t should be that approach. It’s merely a default and good illustration.
What’s vital to grasp is that the weights are assigned from exterior the mannequin and entered it with the question. We’ll cowl why that is vital momentarily.
If we take a look at the term-weight model on the fitting facet, you’ll see that the question “nike trainers” enters BERT (Time period Weighting BERT, or TW-BERT, to be particular) which is used to assign the weights that will be greatest utilized to that question.
From there issues comply with the same path for each, a scoring operate is utilized and paperwork are ranked. However there’s a key remaining step with the brand new mannequin, that’s actually the purpose of all of it, the rating loss calculation.
This calculation, which I used to be referring to above, makes the weights being decided throughout the mannequin so vital. To know this greatest, let’s take a fast apart to debate loss features, which is vital to essentially perceive what’s happening right here.
What’s a loss operate?
In machine studying, a loss operate is principally a calculation of how fallacious a system is with mentioned system making an attempt to study to get as near a zero loss as attainable.
Let’s take for instance a mannequin designed to find out home costs. In case you entered in all of the stats of your home and it got here up with a price of $250,000, however your home offered for $260,000 the distinction can be thought-about the loss (which is an absolute worth).
Throughout a lot of examples, the mannequin is taught to attenuate the loss by assigning completely different weights to the parameters it’s given till it will get the very best outcome. A parameter, on this case, could embody issues like sq. ft, bedrooms, yard dimension, proximity to a faculty, and so forth.
Now, again to question time period weighting
Trying again on the two examples above, what we have to deal with is the presence of a BERT mannequin to supply the weighting to the phrases down-funnel of the rating loss calculation.
To place it in another way, within the conventional fashions, the weighting of the phrases was performed unbiased of the mannequin itself and thus, couldn’t reply to how the general mannequin carried out. It couldn’t learn to enhance within the weightings.
Within the proposed system, this modifications. The weighting is completed from throughout the mannequin itself and thus, because the mannequin seeks to enhance it’s efficiency and cut back the loss operate, it has these further dials to show bringing time period weighting into the equation. Actually.
ngrams
TW-BERT isn’t designed to function when it comes to phrases, however fairly ngrams.
The authors of the paper illustrate nicely why they use ngrams as an alternative of phrases once they level out that within the question “nike trainers” when you merely weight the phrases then a web page with mentions of the phrases nike, operating and footwear might rank nicely even when it’s discussing “nike operating socks” and “skate footwear”.
Conventional IR strategies use question statistics and doc statistics, and should floor pages with this or comparable points. Previous makes an attempt to handle this centered on co-occurrence and ordering.
On this mannequin, the ngrams are weighted as phrases had been in our earlier instance, so we find yourself with one thing like:

On the left we see how the question can be weighted as uni-grams (1-word ngrams) and on the fitting, bi-grams (2-word ngrams).
The system, as a result of the weighting is constructed into it, can prepare on all of the permutations to find out the very best ngrams and likewise the suitable weight for every, versus relying solely on statistics like frequency.
Zero shot
An vital function of this mannequin is its efficiency in zero-short duties. The authors examined in on:
- MS MARCO dataset – Microsoft dataset for doc and passage rating
- TREC-COVID dataset – COVID articles and research
- Robust04 – Information articles
- Frequent Core – Instructional articles and weblog posts
They solely had a small variety of analysis queries and used none for fine-tuning, making this a zero-shot take a look at in that the mannequin was not skilled to rank paperwork on these domains particularly. The outcomes had been:

It outperformed in most duties and carried out greatest on shorter queries (1 to 10 phrases).
And it’s plug-and-play!
OK, that could be over-simplifying, however the authors write:
“Aligning TW-BERT with search engine scorers minimizes the modifications wanted to combine it into current manufacturing functions, whereas current deep studying based mostly search strategies would require additional infrastructure optimization and {hardware} necessities. The realized weights will be simply utilized by commonplace lexical retrievers and by different retrieval methods reminiscent of question enlargement.”
As a result of TW-BERT is designed to combine into the present system, integration is much easier and cheaper than different choices.
What this all means for you
With machine studying fashions, it’s tough to foretell instance what you as an search engine optimisation can do about it (aside from seen deployments like Bard or ChatGPT).
A permutation of this mannequin will undoubtedly be deployed resulting from its enhancements and ease of deployment (assuming the statements are correct).
That mentioned, it is a quality-of-life enchancment at Google, that may enhance rankings and zero-shot outcomes with a low value.
All we are able to actually depend on is that if carried out, higher outcomes will extra reliably floor. And that’s excellent news for search engine optimisation professionals.
Opinions expressed on this article are these of the visitor creator and never essentially Search Engine Land. Workers authors are listed right here.